
Esther Sánchez García and Michael Gasser
Posted November 16, 2021
Lee este artículo en español aquí.
“AI is neither artificial nor intelligent.” —Kate Crawford
In October 2020, four authors submitted a paper to the Association for Computing Machinery Conference on Fairness, Accountability, and Transparency entitled “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” critiquing current research in natural language processing (NLP).1 NLP refers to attempts to develop machines capable of understanding text and spoken language, and has seen a large expansion, in particular with the advent of more and more sophisticated statistical language models as the authors amply document.
Nine days before the paper was accepted for the conference, Timnit Gebru, one of the authors, was fired from her position as co-director of Google’s Ethics team after refusing to retract her name from the paper. Another author and Gebru’s Ethics team co-director, Margaret Mitchell, was fired two months later. Google attracted a media backlash for these actions, for example in The New York Times and Wired.2 Since then, both company and professional colleagues have shown strong support for Gebru and Mitchell.3
Thus the paper’s significance goes beyond purely scientific conclusions; it initiated a discourse on the societal implications of natural language processing (NLP) technology.
But, what are language models? And why would Google want to disassociate itself from criticisms of them?
Some Technical Background
A language model (LM) is a record, for a given body of text (a corpus), of the probabilities of words appearing in particular contexts in the corpus.4 For example, given an English corpus consisting of the Bible, a LM would indicate that the context the beginning of was followed most often by the words creation, reign, and world. It is straightforward to write a program that goes through a corpus and counts all of the occurrences of words and their contexts, resulting in a system called an n-gram model.
However, many LMs nowadays are neural networks.5 These can efficiently learn to associate relatively long contexts – of up to over two thousand words, as compared to around eight for the most complex n-gram models – with the probabilities of different words following them. To do this, they need to be presented with (“trained on”) a very large corpus of hundreds of billions of words. The associations between contexts and following words are implemented in the network in the form of parameters. These models are “big” in the sense that they scale up to trillions of parameters.
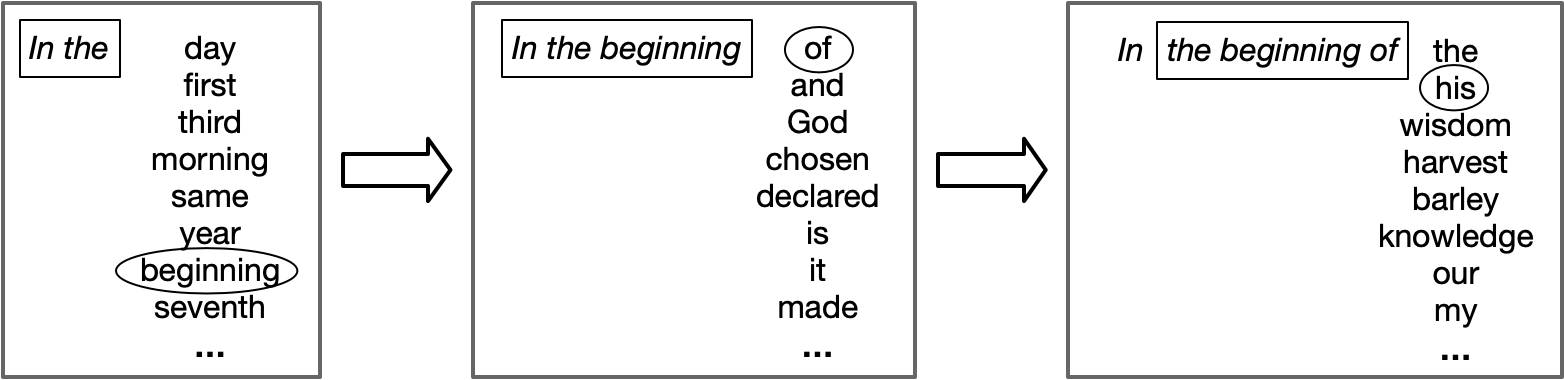
What good is a LM? For one, it can generate texts based on the statistics in a corpus. We start a text off with some words, for instance In the. Again with the Bible as our corpus, our LM tells us that seventy-five words are possible following the context In the. For our text, we could just pick the most common, which happens to be day, but because we’d like to generate a different text each time we run the generator, we instead pick the next word stochastically. In effect, we roll a seventy-five-sided die that is biased towards landing on one side based on the word’s probability of occurring next. Let’s say our die lands on the side representing the word beginning. Next we ask our LM which words can follow In the beginning. We continue until we have the desired amount of text. (See figure 1.) Given a neural LM with a very large number of parameters trained on a very large English corpus, the result looks surprisingly like actual English.
LMs have other functions besides generating text. Tasks such as machine translation (MT), question answering, and automatic speech recognition are all based on basic statistical properties of a language. If we train a neural LM on a very large corpus, we can re-use the model for each new task by, in effect, “telling” it how to solve the task. In practice, this allows researchers to avoid starting from scratch on each new task.
Increasingly large neural LMs based on massive amounts of data are becoming more popular within current NLP research. In the authors’ words, the researchers at Google and elsewhere seem to be operating on the principle “there’s no data like more data.” The research is driven overwhelmingly by the performance of the systems on a small set of evaluation measures, which are often quite arbitrary and far removed from the actual deployment of the systems in the real world. A race is on, with competitors including Google, Facebook, Microsoft, OpenAI, and the Beijing Academy of Artificial Intelligence to develop new flavors of neural networks and to build ever larger LMs.6
The Problem
The paper focuses on three kinds of problems with this technology: the environmental costs, the potential for people to be deceived by the systems, and the biases that are built into the training data and reflected in the systems’ performance.
Training a large neural LM – gradually adjusting the billions or trillions of parameters until the network reaches a given level of performance – is an enormous task, costing millions of dollars and requiring a great deal of energy. While a human being is responsible for five tons of CO2 per year, training a large neural LM costs 284 tons.7 In addition, since the computing power required to train the largest models has grown three hundred thousand times in six years, we can only expect the environmental consequences of these models to increase.
Maybe all this CO2 is worth the effort. There’s no doubt that the performance of the big LMs is impressive. Language generators and MT systems based on these systems produce text that looks a lot like that produced by a person. But is this a good thing? Human communication is oriented towards making sense out of what others are saying or writing, and so we have a strong tendency to find coherence and meaning even when they aren’t there. In the case of text produced by an LM, they aren’t there. A LM knows nothing more than probabilistic information about sequences of words in the corpus it was trained on. There is no communicative goal, no genuine meaning at all behind the text it produces: it is a stochastic parrot. In the wrong hands, it could be a truly dangerous parrot. For example, we could produce huge quantities of seemingly coherent text on a given topic, making it appear that there is great interest among the public in discussing it, or we could generate countless pages of comments on an instance of fake news, reifying the information and effectively rendering it a social reality.
Because the text generated by the big LMs looks genuine, it is reasonable to look more closely at the content, at what these models “know.” Clearly, they are constrained by the data that they are trained on. Our simple model trained on the Bible would obviously be biased towards a particular perspective on the world and would “know” nothing about the developments of the past two thousand years. Though it may be less obvious, a model trained on the data available on the Internet would also have built-in biases because this data is not representative of what all of humanity knows and believes. For example, while Wikipedia is a major source of data for training LMs, only eight-point-eight to fifteen percent of Wikipedians are women. Another important source of data is Reddit, where seventy percent of the users are white and sixty-four percent are under thirty.8 Furthermore, Internet access itself is extremely uneven. According to Our World in Data, in Sub-Saharan Africa only twenty percent of the population uses the Internet, while the number rises to seventy-eight percent in North America.
The Consequences
The paper recognizes some initiatives to offset the environmental impact of training LMs, but is it really worth the effort to allocate renewable energy towards this goal, knowing that the research advances serve the most privileged people (Internet users) when it is the least privileged who suffer the consequences of climate change?
It is also the least privileged who are harmed in another way by the models. As mentioned above, datasets sourced from the Internet codify the hegemonic vision that excludes people on the margins and amplifies the voices of the over-represented. Combined with the fact that the texts generated by these systems appear real, this reproduction of biases toward specific groups can only further ossify the current system of oppression and inequality.
The misplaced confidence in the generated texts or in the output of other systems based on LMs can also lead to serious, unaccountable errors. The authors relate a revealing example in which a Palestinian man was arrested and interrogated by the Israeli police in 2017 after an MT system translated the greeting he had written in Arabic on his Facebook wall to “attack them” in Hebrew. MT offers us access to lots of information, but how much can we trust it in the moments we’re making decisions that affect people’s lives?
The datasets behind these large LMs have another problem—it is costly to update them. As a result, the models tend to remain static and thus underrepresent or misrepresent societal change and movements to further change. The marginalized peoples active in the struggle to better their lives will find themselves faced with a static world of information that is difficult to overcome. We are restricting our possibilities for social change.
Finally, it should not surprise us that work on large LMs is dominated by English, which accounts for more than half of the Internet’s web pages, though it is spoken as a native language by only about five percent of the world’s population. Do we want to continue the hegemony of English and silence all other languages, including the thousands with no digital resources at all?
We are valuing quantity over quality. What should we be doing instead, as scientists and as activists?
The Solutions
If we are to continue with this research, we must attempt to mitigate the various risks and harms the authors describe. None of this is trivial given a research culture obsessed with even tiny increases in “performance.” An immediate action for NLP researchers is to cautiously consider the tradeoff between the energy required and expected benefits. Datasets and the systems trained on them must be carefully planned and documented, taking into account not simply the design of the technology, but also the people who will use it or may be affected by it. Rather than simply grabbing massive quantities of available data from the Internet, the researchers will need to dedicate considerable time to creating datasets that are appropriate for the tasks and, to the extent possible, free from the biases that are present in unfiltered data. From this perspective, “there’s no data like more data” would convert itself to something more like “there’s no data like good data.”
Do the criticisms and proposals in the paper threaten Big Tech’s plans for NLP? Google seemed to think so. Considering that they ousted their Ethics team, one wonders whether Google (and others) can continue to use “ethical” to describe whatever new NLP applications they deploy.
Finally, we should ask whether it is worth pursuing these enormous LMs at all. Won’t the extremely large datasets that are required inevitably bring with them the problems of bias inherent in data that are in no way representative of the general population? Do we really want to continue to benefit those who already gain from this sort of technology and its development? Research time and effort are themselves valuable resources. Is it not time to dedicate them to realigning the research goals in NLP (from a theoretical standpoint) towards a deeper understanding of meaning and communicative intent and (from a practical standpoint) towards work that is tied to social needs and constrained by sustainable resources?
One good example is the growing subfield within NLP dedicated to developing applications in “low-resource” contexts, as exemplified in recent workshops on low-resource MT and NLP for African languages.9 This of course describes the situation that the great majority of the world’s languages (and their communities of speakers) find themselves in. Because the systems built for this kind of research are, by definition, never “big,” they don’t have the environmental costs associated with the systems described in the paper. And, with the support and collaboration of the communities where the languages are spoken, such work has the potential to realize the United Nations Educational, Scientific, and Cultural Organization’s goal of Language Technology For All.10
We should have no illusions about Big Tech; “ethics” will continue to be a cover for their bottomline: profit at the expense of marginalized people. But the research community, like the general public, has ignored, overlooked, or dismissed this. The importance of a work like “Stochastic Parrots” is that it helps to expose Google, Facebook, and other profit seekers for what they really are by highlighting the range of specific problems associated with Big NLP.
This article was originally published in Volume 24, Number 2, Don’t Be Evil of Science for the People and can be found here.
Notes
- Emily M. Bender et al., “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? ,” in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21 (New York, NY, USA: Association for Computing Machinery, 2021), 610–23.
- Cade Metz and Daisuke Wakabayashi, “Google Researcher Says She Was Fired Over Paper Highlighting Bias in A.I,” The New York Times, December 3, 2020, https://www.nytimes.com/2020/12/03/technology/google-researcher-timnit-gebru.html; Tom Simonite, “What Really Happened When Google Ousted Timnit Gebru,” Wired, June 8, 2021, https://www.wired.com/story/google-timnit-gebru-ai-what-really-happened/.
- Google Walkout For Change, “Standing with Dr. Timnit Gebru — #ISupportTimnit #BelieveBlackWomen,” Medium, December 4, 2020, https://googlewalkout.medium.com/standing-with-dr-timnit-gebru-isupporttimnit-believeblackwomen-6dadc300d382; Megan Rose Dickey, “Google Fires Top AI Ethics Researcher Margaret Mitchell,” TechCrunch, February 19, 2021, http://techcrunch.com/2021/02/19/google-fires-top-ai-ethics-researcher-margaret-mitchell/.
- Daniel Jurafsky and James H. Martin, “N-Gram Language Models,” IEEE Transactions on Audio, Speech, and Language Processing 23 (2018).
- Yoav Goldberg, “A Primer on Neural Network Models for Natural Language Processing,” The Journal of Artificial Intelligence Research 57 (November 20, 2016): 345–420.
- “Natural Language Processing,” Facebook AI, accessed July 9, 2021, https://ai.facebook.com/research/NLP/; Alec Radford et al., “Better Language Models and Their Implications” Open AI (blog), February 14, 2019, https://openai.com/blog/better-language-models/; Coco Feng, “US-China Tech War: Beijing-Funded AI Researchers Surpass Google and OpenAI with New Language Processing Model,” South China Morning Post, June 2, 2021, https://www.scmp.com/tech/tech-war/article/3135764/us-china-tech-war-beijing-funded-ai-researchers-surpass-google-and.
- Hannah Ritchie and Max Roser, “CO₂ and Greenhouse Gas Emissions,” Our World In Data, Oxford Martin School, May 11, 2020, https://ourworldindata.org/co2-emissions.
- Michael Barthel et al., “Reddit News Users More Likely to Be Male, Young and Digital in Their News Preferences,” PEW Research Center, February 25, 2016, https://www.journalism.org/2016/02/25/reddit-news-users-more-likely-to-be-male-young-and-digital-in-their-news-preferences/.
- “Proceedings of the 3rd Workshop on Technologies for MT of Low Resource Languages – ACL Anthology,” ACL Anthology, accessed July 9, 2021, https://aclanthology.org/volumes/2020.loresmt-1/; “Program: Putting Africa on the NLP Map,” ICLR 2020, accessed July 9, 2021, https://africanlp-workshop.github.io/program.html.
- “Homepage,” LT4All: Language Technologies for All, accessed July 9, 2021, https://lt4all.org/en/.